

Tier 4 is the highest standard for data center reliability, guaranteeing 99.995% uptime and limiting annual downtime to 26.3 minutes. It gets there through full fault tolerance and a 2N+1 design for critical systems, so a single failure in power or cooling doesn’t interrupt the IT load.
If you’re reading this, you’re probably not trying to build a giant hyperscale campus. You’re more likely deciding where to place critical infrastructure, whether to move production workloads into colocation, or whether a managed private cloud can deliver the resilience your business needs.
That decision gets expensive fast when vendors throw around phrases like “Tier 4-ready,” “fault tolerant,” and “enterprise-grade.” Some of those claims describe real engineering. Some are just polished sales language. The difference matters when your ecommerce store, ERP platform, phone system, client portal, or healthcare application can’t afford an outage at the wrong moment.
The practical question for most CIOs isn’t “Is Tier 4 impressive?” It is. The key question is whether your business needs certified Tier 4 infrastructure, or whether you can get the operational outcome you care about through smarter architecture in colocation or a managed private cloud. That’s where most growing businesses should focus.
Introduction When Downtime Is Not an Option
A regional business can hit enterprise-grade risk long before it reaches enterprise scale. One online retailer with a lean IT team may only run a few production systems, but if the storefront, payment workflow, and inventory sync all depend on the same infrastructure window, a short outage can turn into a revenue event, a support event, and a trust event at the same time.
The same pattern shows up in professional services, healthcare-adjacent firms, logistics companies, and multi-location businesses. Their infrastructure often started small, then accumulated dependence. A web front end ties into a database. The database ties into reporting. Email and VoIP rely on the same network edge. Suddenly, “just a few minutes” isn’t minor anymore.
Practical rule: If a single infrastructure failure would stop revenue, operations, or customer access, you need to evaluate facility resilience separately from server specs.
That’s why Tier 4 matters. Not because every business should pursue it, but because it gives you a clean definition of what the top end of resilience looks like. Once you understand that standard, you can judge whether a provider’s design is fault tolerant or just broadly redundant.
For some organizations, certified Tier 4 is justified. For many SMEs, it’s overkill at the facility level but still useful as a design reference. You can borrow the right ideas, isolate failure domains, duplicate critical paths, and place the right workloads in the right hosting model. That usually leads to a better business decision than chasing the highest label on paper.
What Exactly Is a Tier 4 Data Center
A Tier 4 data center is the top level in the Uptime Institute’s classification model. It is the only level defined as fully fault tolerant, with 99.995% annual uptime and a maximum of 26.3 minutes of downtime per year, as described in CoreSite’s breakdown of data center tiers.
That definition matters because many teams confuse redundancy with fault tolerance. Redundancy means you have backups. Fault tolerance means the environment continues operating when something fails, without the IT load dropping.
Redundancy is not the same as fault tolerance
A simple way to think about it is a hospital power design. A backup generator is helpful, but it’s still a backup event. A fault-tolerant design assumes a component or path can fail and the critical load remains supported through another active path.
In Tier 4, the facility removes single points of failure and uses 2N+1 architecture for critical systems. In practical terms, that means the site has full duplicate capacity for the required load, plus an additional backup component. Power and cooling aren’t treated as nice-to-have support systems. They’re engineered as active, resilient infrastructure.
How Tier 4 compares with lower tiers
The easiest way to understand Tier 4 is to place it next to the lower tiers.
| Feature | Tier 1 | Tier 2 | Tier 3 | Tier 4 |
|---|---|---|---|---|
| Basic resilience level | Basic infrastructure | Added redundant components | Concurrently maintainable | Fully fault tolerant |
| Power and cooling approach | Single path | Single path with more component backup | Multiple paths for maintenance resilience | Fully independent active paths |
| Maintenance impact | Maintenance can interrupt service | Maintenance risk remains significant | Planned maintenance can be done without shutdown | Planned and unplanned single failures should not interrupt IT load |
| Single points of failure | Present | Can still exist at path level | Reduced, but not fully eliminated for all failure scenarios | Zero single points of failure |
| Typical fit | Labs, noncritical workloads | Smaller production environments | Most enterprise colocation and production hosting | Mission-critical environments where downtime is unacceptable |
Most businesses shopping for colocation hosting don’t need to insist on Tier 4 certification for every workload. They do need to understand what problem Tier 4 solves, because that affects how they evaluate facilities, private cloud designs, and managed hosting architectures.
Tier 4 is less about “more backup gear” and more about whether one real-world failure can occur without taking your systems down.
What the label should mean to a buyer
When a provider says “Tier 4,” the right response is to ask whether they mean official certification or a design aspiration. Uptime Institute requires formal review. A facility can’t declare itself Tier 4 based on internal opinion or marketing copy.
For a CIO, that distinction is useful because it separates engineering claims from audited infrastructure. If the workload cannot stop, verification matters. If the workload can tolerate some design trade-offs, then the facility label is only one part of the decision. Network layout, host architecture, cluster design, backup strategy, and operational discipline all matter too.
The Core Technical Requirements for Tier 4
A Tier 4 build is defined by engineering discipline, not by broad promises. Uptime Institute frames Tier IV around fault tolerance, with fully independent and physically isolated critical power and cooling paths so that any single failure does not interrupt the IT load. It also requires all IT equipment to be compatible with a fault-tolerant power design, as outlined by the Uptime Institute tier standard.
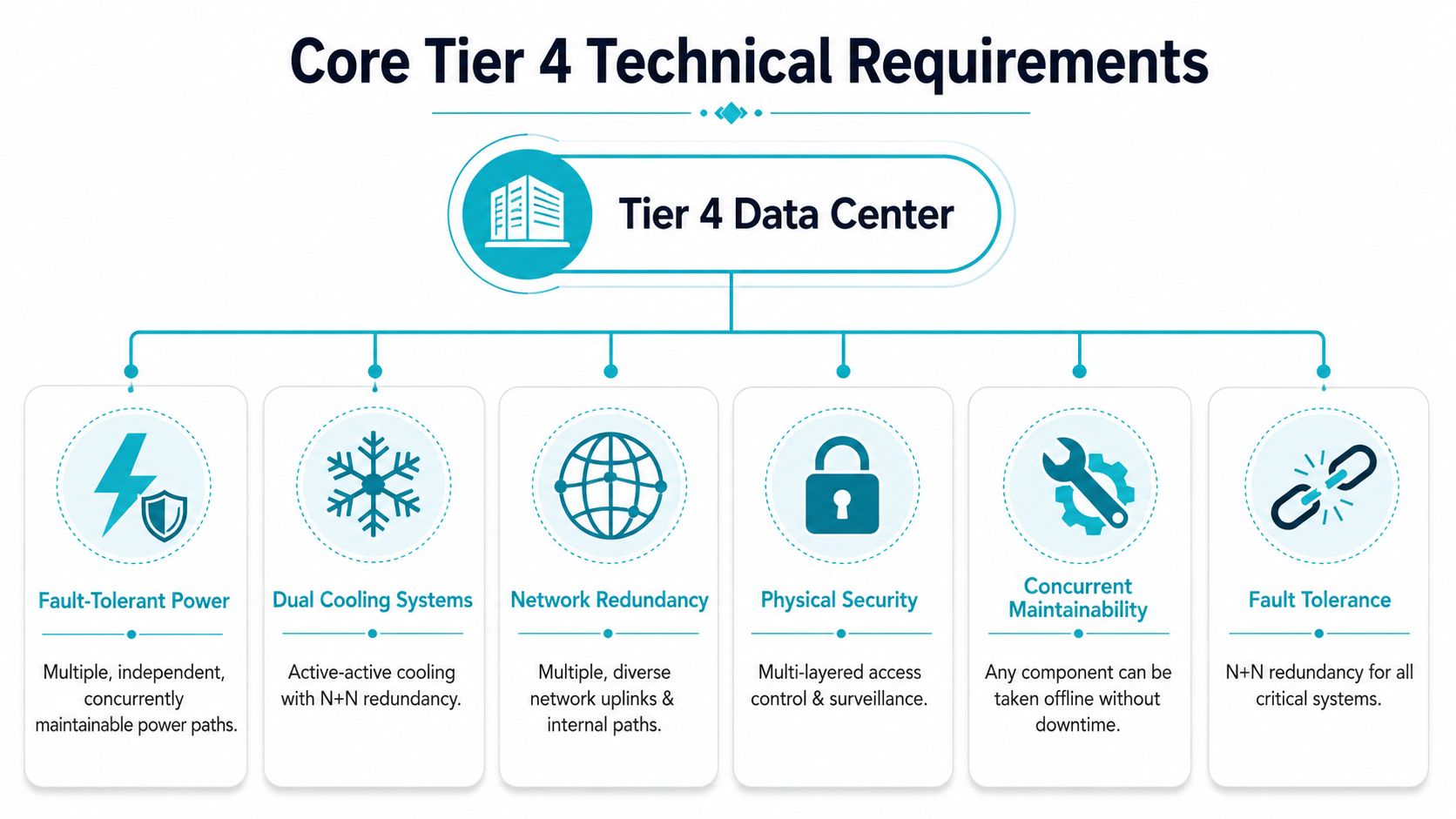
Power paths must be independent
Many “high availability” claims fall apart under these circumstances. Dual UPS units in the same logical chain don’t create fault tolerance if a single upstream event can still take out both paths.
A real Tier 4 power design keeps critical paths independent and physically separated. That includes utility entrance strategy, UPS architecture, generator support, switchgear arrangement, and rack-level delivery to equipment that can consume dual power feeds correctly.
If you want a practical primer on how to evaluate path diversity around networking as well as facilities, this guide on network redundancy fundamentals is a useful companion when you’re reviewing provider designs.
Cooling has to survive failure without drama
Cooling gets oversimplified by non-operators. Teams ask whether a facility has redundant cooling, but the better question is whether cooling remains effective during both maintenance and unexpected failure.
Tier 4 expects cooling paths to be isolated in the same spirit as power paths. If one mechanical chain fails, the remaining path must continue supporting the environment. That means design discipline around chillers, pumps, CRAH or CRAC strategy, piping paths, controls, and room-level airflow behavior.
For teams that want to go deeper on cooling decisions and field implementation, data center HVAC best practices for integrators is worth reviewing because it connects design intent with operational reality.
Concurrent maintainability is mandatory
A resilient facility can’t require downtime every time something needs service. In practice, this means operators must be able to isolate, repair, replace, or maintain components without dropping the protected load.
That sounds simple until you trace actual dependencies. A provider may have duplicate components, but if maintenance on one path forces a risky transfer or creates a temporary single-path condition, you don’t have the same outcome as a design with true fault tolerance.
A mature facility team doesn’t just have redundant equipment. They can explain which component can be removed from service today, and why production stays up while they do it.
Physical isolation matters as much as duplication
This is one of the least understood parts of Tier 4. Two systems placed too close together can still fail together. Shared risk can come from fire exposure, water events, maintenance error, cable routing, or poor compartmentalization.
That’s why the strongest facility designs think in failure domains, not just inventory counts. Separate paths. Separate rooms where needed. Separate distribution logic. The goal is simple. One incident should not propagate into both sides of the architecture.
Understanding the Operational and Cost Implications
The technical elegance of Tier 4 comes with a hard business reality. Duplicating critical systems, isolating paths, and operating a fault-tolerant environment pushes both construction complexity and ongoing operations well beyond what most private organizations should own themselves.

Why private Tier 4 is often the wrong move for SMEs
Even when the uptime goal is valid, owning the entire facility stack usually isn’t. You’re not just paying for generators, UPS systems, cooling plants, and electrical design. You’re committing to an operational model that demands strong procedures, experienced facilities staff, disciplined maintenance windows, and continuous oversight of infrastructure most software-oriented businesses were never meant to run.
That’s why many CIOs do better by separating two questions:
- Facility resilience: What level of site engineering do we need under our hardware?
- Application resilience: How should we design the workload to survive host, node, or zone-level failure?
Those are related, but they aren’t the same purchase.
Colocation changes the math
Colocation is often the most rational path when your workloads need serious infrastructure support but your business doesn’t need to own a facility. You place your servers in a provider-operated environment and buy access to resilient power, cooling, physical security, and network options as a service.
That keeps capital focused on compute, storage, and application design instead of building systems that don’t directly create business value. It also gives you room to choose between single-server deployments, clustered virtualization, database replicas, or managed private cloud layouts.
For buyers comparing options, reviewing data center colocation pricing is usually more useful than asking abstract questions about “enterprise readiness.” Pricing structure often reveals whether a provider is set up for practical production use or just basic rack space rental.
Most growing businesses shouldn’t try to own a Tier 4 outcome at the building level. They should buy the right facility foundation and spend the rest of the budget on resilient service architecture.
What works better in practice
For SMEs and growth-stage companies, the sweet spot is often one of these models:
- Colocation for fixed critical infrastructure when you need control over hardware, firewalls, storage, or virtualization nodes.
- Managed private cloud when you want isolation and cluster-level resilience without owning the operational burden.
- Hybrid deployment when some systems belong on dedicated hardware and others fit better on virtualized platforms with managed backups and monitoring.
What doesn’t work is paying premium rates for a “Tier-like” environment while still running single points of failure inside it. A resilient building won’t save a fragile application design.
Building Tier 4 Resilience with ARPHost Solutions
A growing company usually feels the underlying availability problem during an ordinary week, not during a disaster. A host needs patching at 2 p.m. A storage node throws errors. A firewall upgrade cannot wait for the next quarter. The question is whether the business keeps operating while infrastructure work happens.
For many SMEs, the answer is not a certified Tier 4 deployment. It is an architecture that limits the blast radius of a single failure and gives operations teams a clean recovery path. That can be built inside a well-run colocation environment or a managed private cloud, provided the design is honest about what it can and cannot survive.
A practical design that closes most of the gap
One of the most effective patterns is a small virtualization cluster on dedicated hardware, with clear separation between compute, storage, backup, and management. In practical terms, that often means two or more Proxmox nodes for production workloads, external backups that do not share the same failure domain, and failover policies based on application priority rather than guesswork.
Hardware choice matters because resilience starts with capacity headroom. A pair of Dual Intel Xeon E5-2690 V3 servers with 28 cores and 64GB DDR4 ECC RAM each can support a modest footprint of web, database, and internal business systems. If the environment is memory-heavy, storage-sensitive, or expected to consolidate more virtual machines per host, an AMD EPYC 4584PX with 16 cores and 192GB DDR5 RAM is a better fit.
That still is not Tier 4. It is often enough.
Where near-Tier-4 outcomes actually come from
The gain comes from disciplined design choices, not from marketing labels. Put primary and secondary services on different nodes. Keep management access separate from tenant traffic. Place backups and replicas outside the same production cluster when recovery time matters. Avoid stacking the firewall, shared storage, and every customer-facing workload onto one server and calling it highly available.
Operations usually decide whether a good design holds up under pressure. Planned maintenance, firmware updates, failed disks, and misconfigurations cause more downtime than dramatic building failures. A managed operating model reduces that risk because patching, monitoring, backup verification, and cluster maintenance are handled with a repeatable process instead of ad hoc effort.
ARPHost, LLC fits this model with colocation, dedicated infrastructure, Proxmox private cloud options, and managed support for businesses that need stronger continuity without funding a fully certified Tier 4 footprint.
When this approach makes financial sense
For a mid-market business, the trade-off is straightforward. Full Tier 4 certification is justified when the cost of interruption is extreme, the compliance requirement is explicit, or the application cannot tolerate concurrent failures and maintenance events. Many companies do not live in that category. They need high availability for core systems, defined recovery objectives, and an operations team that can execute.
A managed private cloud or strategic colocation design often gets much closer to the business outcome that leadership cares about. Revenue systems stay online during routine maintenance. Recovery after a host failure is measured and tested. Budget stays available for replication, backups, monitoring, and application hardening instead of being consumed by facility prestige alone.
The target is continuity for the workloads that matter most, with a cost structure the business can sustain.
That is usually the more mature decision.
A Practical Checklist for Vetting Providers
A provider can sound credible and still leave major resilience gaps hidden in the fine print. The safest way to evaluate hosting, colocation, or managed private cloud options is to ask operational questions that force concrete answers.
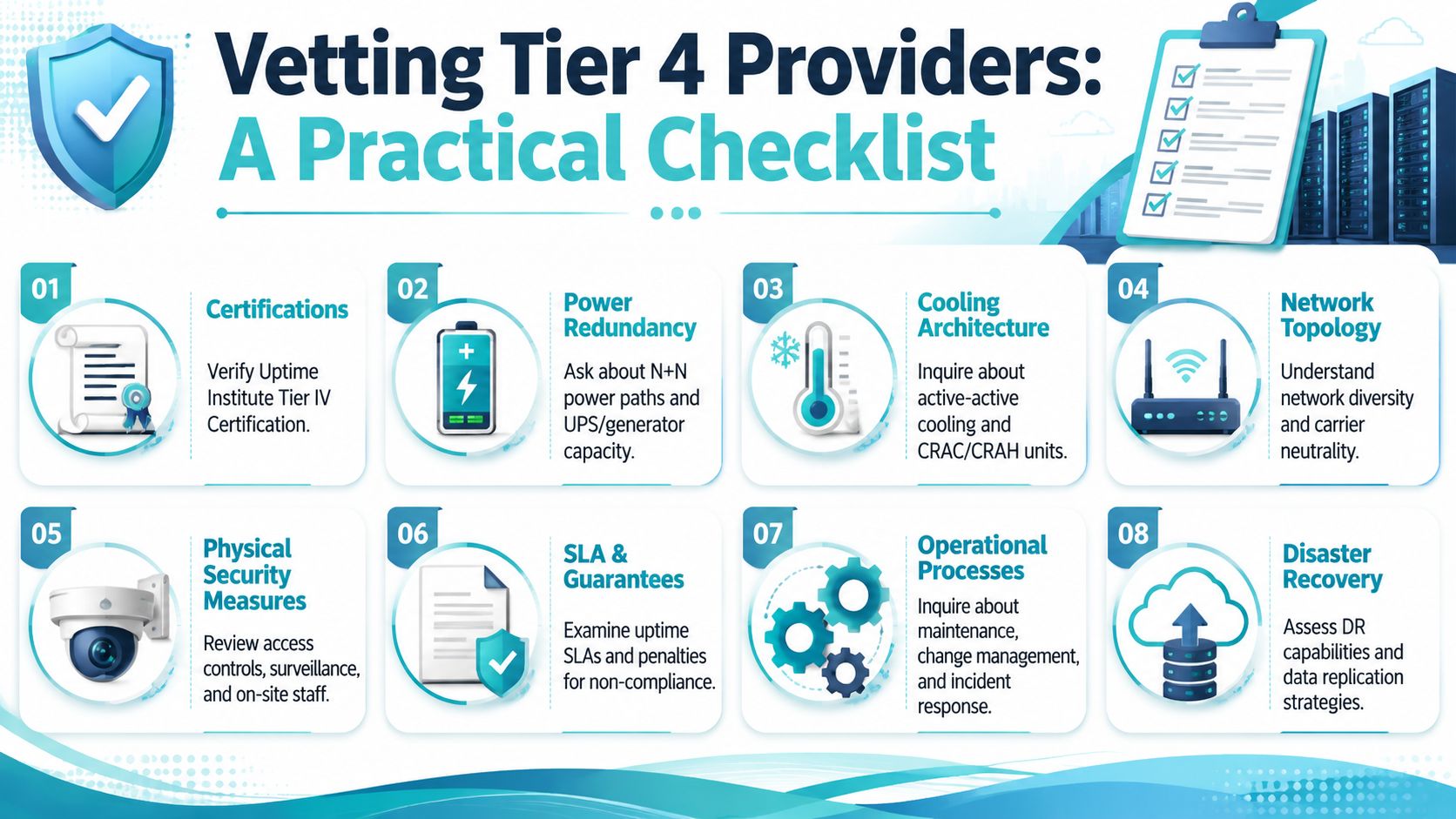
Questions that expose the real design
Bring this list into every provider conversation:
- Certification status: Ask whether the facility is officially certified or merely designed with similar principles. If they claim Tier 4, request proof of external verification.
- Power architecture: Ask how critical loads are fed, how paths are isolated, and whether customer equipment can take dual independent feeds.
- Cooling resilience: Ask what happens during maintenance on a major cooling component and what protects the room during an unexpected failure.
- Network diversity: Ask which upstream carriers are available and whether internal network paths are built with failure isolation in mind.
- Maintenance process: Ask how the provider performs routine work without customer downtime and what change control looks like.
- Remote hands and support model: Ask who is onsite, what they can do, and how quickly they can respond to hardware issues.
- Security controls: Ask how they separate customer access, cabinet access, visitor control, and monitoring.
- Recovery planning: Ask where backups live and how they would help you recover from a host failure, storage problem, or site-level issue.
What good answers sound like
Strong providers answer directly and operationally. They don’t hide behind “enterprise-grade” language. They describe path separation, maintenance workflows, equipment compatibility, and the exact boundary between facility responsibility and customer responsibility.
Weak providers answer with labels only. They say “fully redundant” but can’t tell you whether paths are active, isolated, or dependent on manual intervention. That’s usually your signal to slow down.
Ask providers to explain a failure scenario in plain language. “If this UPS chain fails, what happens next?” If the answer gets vague, the design probably is too.
Use the checklist for private cloud too
This applies beyond colocation. If you’re buying a managed private cloud, the same questions still matter. You’re just adding virtualization, storage, monitoring, and failover operations to the evaluation.
A private cloud host should be able to explain how the physical layer supports the virtual layer. If they can’t connect those two stories clearly, you’re not looking at a mature platform.
Frequently Asked Questions About Tier 4 Data Centers
How does Tier 4 compare with a public cloud availability zone
They address different layers of the problem.
Tier 4 describes the resilience of a physical facility: power, cooling, distribution paths, maintenance isolation, and fault tolerance at the building level. A public cloud availability zone is part of a platform architecture. It gives you a place to spread workloads, but it does not remove the need to design for failure.
That distinction matters for SMEs. A business can run highly available services in public cloud without ever touching a Tier 4 facility, if the application is built across zones and regions properly. The trade-off is operational complexity, variable cloud spend, and more responsibility for the way storage, failover, and dependencies are configured.
Does my business really need Tier 4
Usually, no.
Certified Tier 4 makes sense when interruption has outsized consequences, such as regulated operations, hard uptime commitments, or systems tied directly to safety, financial settlement, or critical production. For many growing businesses, the requirement is narrower. They need predictable uptime, clean maintenance windows, strong backup discipline, and a recovery plan that works under pressure.
For that group, a well-run colocation deployment or managed private cloud often lands in the right place. You can get very high reliability without paying for the full certification path, provided the environment is designed around realistic failure scenarios.
The better question is not “What is the highest tier?” It is “Which systems justify the cost of maximum facility resilience, and which systems can be protected through architecture, replication, and recovery planning?”
What is the difference between designed to Tier 4 and certified Tier 4
The difference is independent validation.
“Designed to Tier 4” usually means the provider states that its facility follows Tier 4 design principles. “Certified Tier 4” means the design and, in some cases, the constructed facility or operational practices have been reviewed through the Uptime Institute process rather than asserted by the operator alone.
That gap matters in procurement. If the business is accepting legal exposure, contractual penalties, or major revenue loss from downtime, self-described alignment is not the same as certification. If your needs are less rigid, a provider with strong engineering discipline and transparent operating procedures may still be a sound fit. The key is to treat those labels differently during evaluation.
When is Tier 4 overkill
Tier 4 is overkill when the cost of achieving that last increment of facility resilience is higher than the business impact it removes.
I see this most often with SMEs that have important systems but not mission-critical single-site dependencies. Typical examples include ecommerce platforms with acceptable failover options, line-of-business applications that can tolerate controlled recovery, and firms that care more about restoring service quickly than about maintaining every workload through any facility event without interruption.
In those cases, the better investment is usually selective. Put the workloads that need fixed performance on dedicated infrastructure. Cluster the systems that justify it. Keep backups separate from production. Use a quality colocation facility or a managed private cloud with clear operational ownership. That gets many businesses close to the outcome they want, without taking on the full cost structure of a certified Tier 4 strategy.
If you’re weighing colocation against managed private cloud, or trying to map real uptime requirements to an affordable architecture, ARPHost, LLC offers a practical mix of colocation, VPS hosting, and secure web hosting bundles for businesses that need stronger resilience without building a facility of their own.