

Miami isn’t just another place to rent racks. It sits at the intersection of U.S. infrastructure demand, cross-border traffic, and regional application delivery. That combination changes the hosting conversation for both SMBs and larger IT teams.
If you’re evaluating Miami data centers, the right question isn’t ‘which facility has space?’ It’s ‘which operating model gives us the network reach, control, and operational support we need?’ For some teams, that’s colocation in a carrier-dense building. For others, it’s managed bare metal in Florida. For many, it’s a private cloud that keeps dedicated performance without forcing the business to run a full data center practice in-house.
Why Miami Is a Global Digital Crossroads
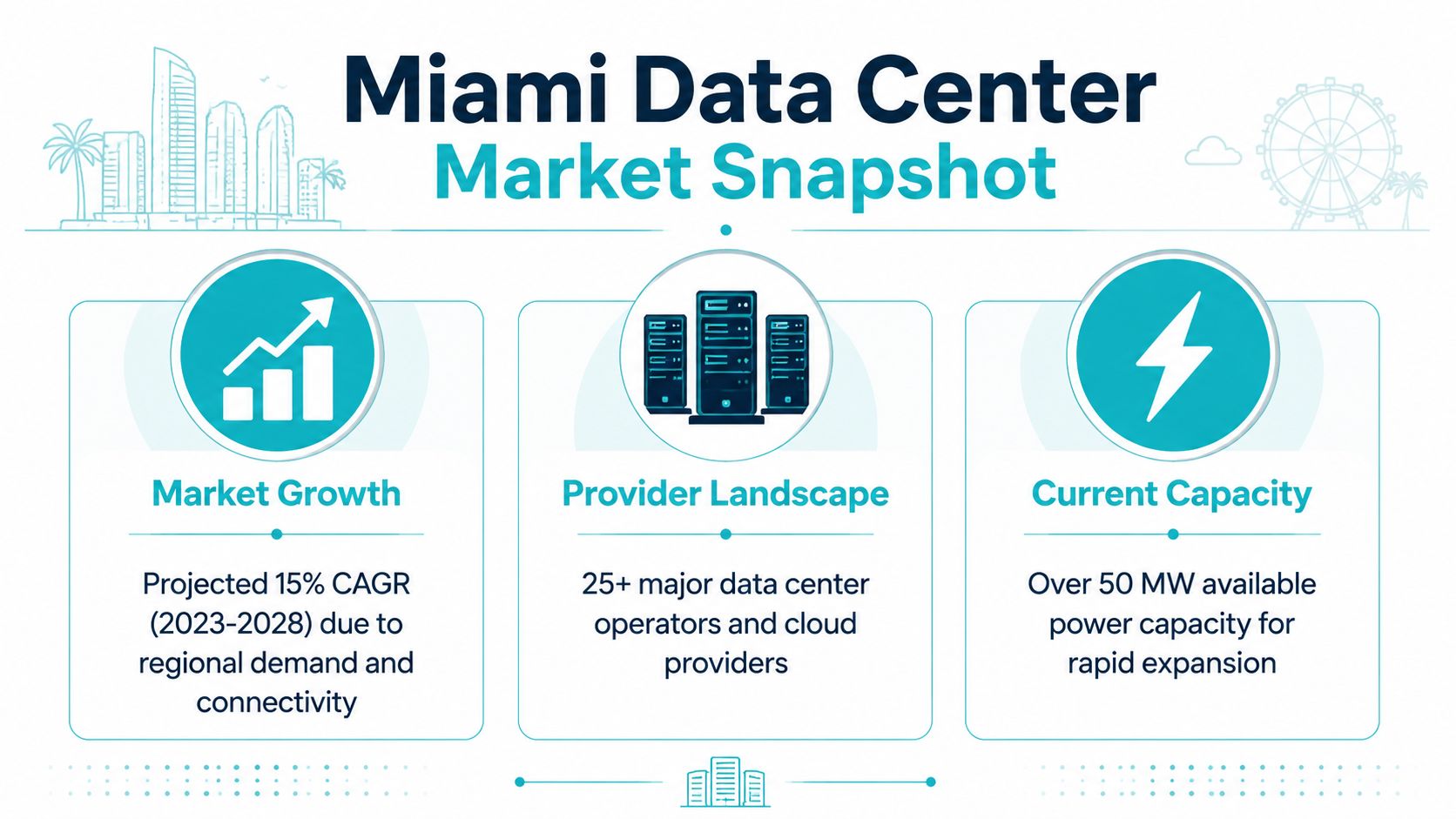
Miami’s digital economy includes more than 36,000 tech businesses, is growing at 4.8% annually, and attracted over $5 billion in capital inflow during 2022, while the local data-center market showed a 16.4% vacancy rate with 56 MW in the pipeline, according to Iron Mountain’s Miami market overview. That combination matters because it signals two things at once. Demand is real, and expansion is active.
The more important point for infrastructure buyers is strategic rather than statistical. Miami has become a practical landing point for organizations that need strong U.S. hosting while staying close to users, partners, and networks across Latin America and the Caribbean. That changes routing choices, disaster-recovery planning, and where teams place latency-sensitive application tiers.
Why this market feels different
A lot of metro markets are evaluated on rent, power, and available cabinets. Miami data centers require a broader lens.
- Regional reach matters: A deployment in Miami can support U.S. operations while remaining well positioned for cross-border connectivity patterns.
- Interconnection matters: Buyers aren’t only shopping for floor space. They’re often shopping for access to carriers, cloud paths, and exchange-rich environments.
- Disaster recovery matters: Teams that don’t want every critical system tied to one geography often look at South Florida as part of a broader Florida strategy.
Practical rule: If your users, customers, or business partners span North America and Latin America, treat Miami as a network decision first and a real estate decision second.
That distinction is where many buying processes go wrong. Teams compare rack pricing or server specs before deciding whether they need a carrier-neutral environment, managed hosting, or a private cloud abstraction layered on dedicated hardware.
For companies that need a neutral interconnection environment, a carrier-neutral data center option can make more sense than committing early to a single-provider design. The win isn’t just connectivity. It’s preserving architectural flexibility while your traffic patterns, vendors, and compliance requirements evolve.
An Overview of the Miami Data Center Market
Miami’s role in digital infrastructure isn’t new. A major downtown facility opened in 2001 at 750,000 square feet, helping establish the city as a computing hub for much of Latin America, and more recent reporting says the area has at least 27 data centers built or under construction, while Florida overall has 120 operating facilities with 8 more planned, according to the Miami Herald’s reporting on the market.
That history matters because Miami didn’t emerge as a data center market by accident. It developed around a role. The city became useful as a cross-border exchange point, a regional hosting base, and a practical place to aggregate connectivity.
Who benefits most from this market
Some workloads gain more from Miami than others.
Media platforms benefit when they need predictable delivery into multiple regions. Financial services teams care about route efficiency, partner connectivity, and dense interconnection ecosystems. SaaS providers care about placing customer-facing services where network paths stay short and stable. Enterprises with branch footprints across the Americas often value Miami as a regional anchor for identity, edge services, or disaster recovery.
A common mistake is assuming every workload should live in Miami just because the market is strategically important. That’s not how experienced teams decide. They separate workloads into categories:
| Workload type | Good fit for Miami | Better elsewhere |
|---|---|---|
| Regional app front ends | Strong fit when user distribution spans the Americas | Less compelling if users are concentrated in one distant metro |
| Interconnection-heavy services | Strong fit in carrier-dense environments | Weaker fit for isolated internal systems |
| Disaster recovery replicas | Useful as part of a multi-site strategy | Poor choice if you need a totally different regional risk profile |
| Back-office batch processing | Sometimes | Often better placed where power, support, or existing operations are simpler |
What the mature buyers check first
The strongest evaluations don’t start with sales brochures. They start with operating constraints.
- User geography: Where do users connect from?
- Application sensitivity: Does the workload care about latency variance or just general availability?
- Support model: Does your team want to manage hardware and network relationships directly?
- Expansion path: Can your chosen environment scale without forcing a redesign six months later?
Miami works well when the application architecture matches the city’s network role. It works poorly when teams choose it for prestige, then discover their real bottleneck is operational complexity.
Miami data centers are most valuable when they solve a routing, reachability, or resilience problem. If they don’t, another Florida deployment model can still deliver the business outcome with less overhead.
The Connectivity Advantage of Latency and Peering
Miami’s network value shows up in application behavior, not in facility size. In a major interconnection site such as Equinix’s Miami MI2 facility overview, the mix of cross-connects, internet exchange access, cloud on-ramps, and carrier options gives IT teams more control over how traffic moves between users, clouds, partners, and core systems.
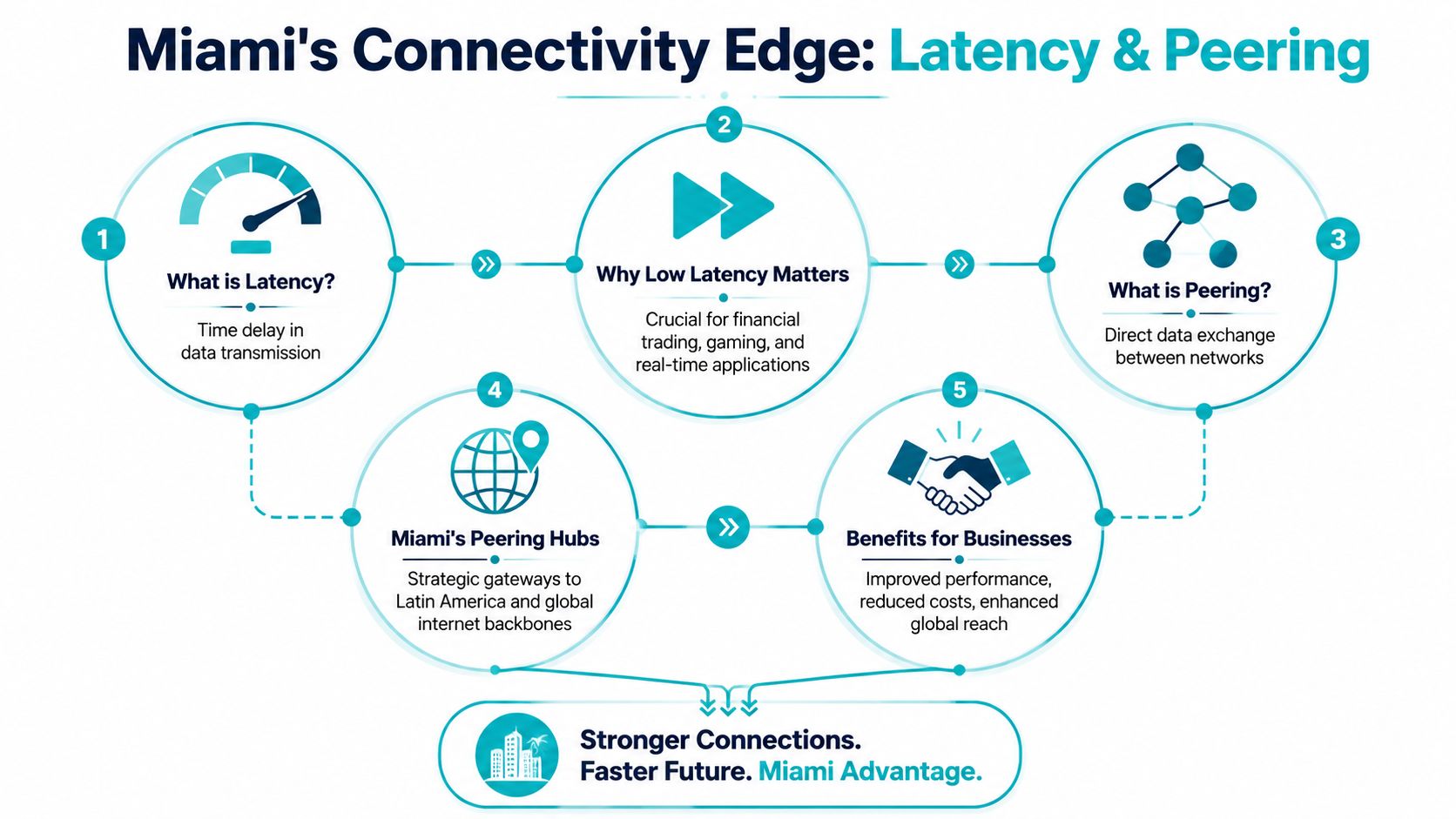
What latency means in buying terms
Latency is the time between a request and a response. For buyers, the more useful question is where delay enters the transaction path.
A workload can run on fast hardware and still perform poorly if traffic takes indirect routes to cloud services, payment processors, identity platforms, or regional users. That is why Miami often makes sense for deployments serving the U.S., Latin America, and the Caribbean at the same time. The city can shorten or stabilize network paths that would otherwise bounce through less efficient exchange points.
Three situations usually justify closer scrutiny of Miami connectivity:
Regional SaaS delivery
If users are distributed across multiple countries and metros, route efficiency often matters more than a modest savings on base infrastructure.Partner-dependent platforms
Financial systems, B2B applications, media delivery chains, and customer portals often depend on consistent exchange with third-party networks.Hybrid environments
If the stack spans colocation, bare metal, and cloud, interconnection choices start affecting operations as much as performance.
The practical takeaway is simple. Buyers should evaluate latency by tracing dependencies, not by reading a generic speed claim on a provider page.
What peering changes operationally
Peering changes more than round-trip times. It changes predictability, fault isolation, and the amount of troubleshooting your team has to own.
When a facility offers dense carrier presence and direct exchange options, traffic can stay closer to its destination instead of traversing multiple public internet hops. That usually reduces jitter and makes behavior more consistent for login flows, API calls, voice traffic, virtual desktops, and multi-service web applications. It also gives network teams clearer escalation paths when performance drops, because fewer external variables sit between your rack and the destination network.
Buyers need a decision framework, not a directory. Ask:
- Which carriers are physically available in the building?
- Can you cross-connect to the networks your application depends on most?
- Do you need private access to cloud platforms, or is internet transit sufficient?
- Will your team manage routing and carrier relationships directly, or do you want that handled for you?
In Miami, network adjacency can outweigh a small monthly price difference. A cheaper cabinet in a weakly connected facility can cost more over time if it adds latency, troubleshooting overhead, or provider sprawl.
Why managed network operations can be the safer choice
This is also where infrastructure model selection becomes clearer. Enterprises with in-house network engineering may benefit from colocation in a carrier-dense site, especially when they need direct control over peering, routing policy, and cross-connect design. SMBs and mid-market teams often want the outcome instead: stable performance, accountable support, and a Florida footprint without managing every carrier contract themselves.
ARPHost, LLC fits that second requirement well. Teams that do not need to build their own interconnection strategy from the ground up can use managed hosting, bare metal, or private cloud options to get the benefits of a well-placed deployment with less operational burden. That is usually the smarter choice when the business goal is dependable application delivery, not running a networking project inside the hosting project.
Key Technical and Compliance Selection Criteria
When teams shortlist Miami data centers, they often focus too much on location and not enough on electrical design, operating procedures, and support boundaries. That’s risky. A facility that looks strong on paper can become a bad fit if the rack power design, remote hands model, or compliance documentation doesn’t match your workload.

Power architecture isn’t a footnote
Some Miami facilities offer a mix of 120V/208V and 240V/415V distribution, and one published Miami specification lists N+1 standby redundancy with generator capacity of 6 × 1,100 kW plus 6 × 1,760 kW, according to Summit’s Miami technical datasheet. The useful takeaway isn’t the generator count by itself. It’s that facility power design directly affects what you can deploy efficiently.
Higher-voltage distribution is generally more suitable for modern high-density racks. If you’re planning dense virtualization hosts, storage-heavy nodes, or GPU-adjacent infrastructure, voltage and breaker design deserve real scrutiny. Teams that ignore this often end up artificially spreading workloads across more cabinets or redesigning power layouts later.
A practical facility checklist
Use a technical review that goes beyond the sales tour.
- Power fit: Match rack density, PDU design, and expected growth to the facility’s available electrical standards.
- Remote operations: Verify what remote hands can do. Reboots and cable checks are not the same as meaningful operational support.
- Security controls: Ask how access is logged, who can authorize entry, and how visitor handling works.
- Compliance evidence: Don’t stop at a verbal assurance. Confirm what documentation is available for your audit process.
- Cooling and airflow: Ask how the facility handles dense cabinets, not just standard footprints.
What works and what doesn’t
What works is aligning technical design to workload behavior. For example, a private virtualization cluster with aggressive consolidation ratios should be placed where power delivery, failover design, and support response are all compatible with that density.
What doesn’t work is buying on a generic checklist. I’ve seen teams approve a facility because it had “redundant power” without checking voltage options, cabinet constraints, or who owns the problem when a failed component needs hands-on attention at night.
Field note: If your application owners are asking for faster growth, higher density, or stronger compliance posture, your facility decision has already become an operations decision.
For businesses that don’t want to manage those layers alone, managed hosting and managed IT services often reduce risk more effectively than a purely self-operated colocation footprint.
Choosing Your Model Colocation vs Bare Metal vs Private Cloud
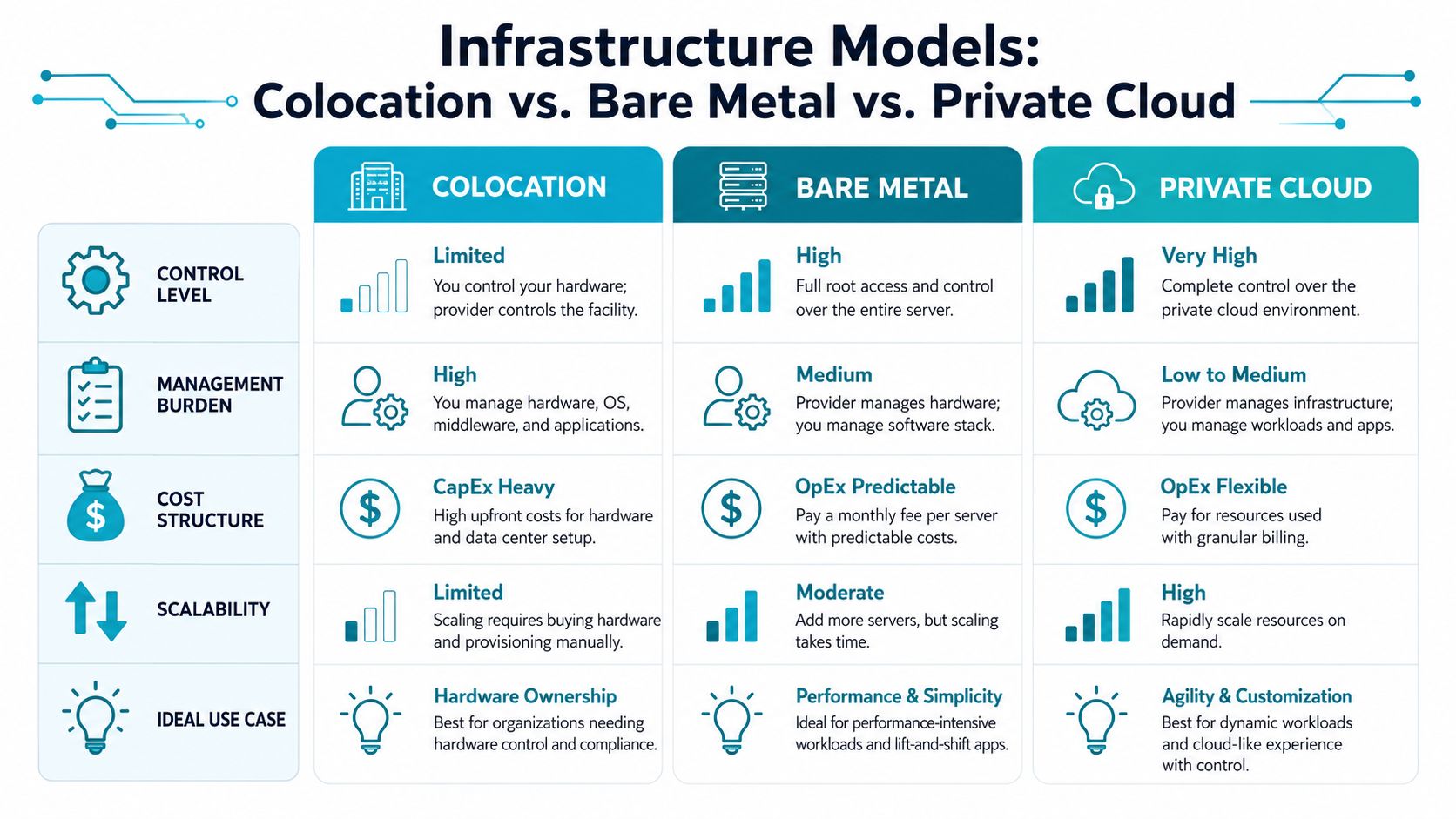
The biggest mistake in Miami infrastructure planning is treating colocation, bare metal, and private cloud as interchangeable. They aren’t. Each model solves a different operational problem.
Colocation makes sense when you want facility access, not service abstraction
Colocation is the right fit when you already own hardware, need strict control over the stack, and have staff who can manage servers, firewalls, hypervisors, replacements, and vendor coordination. It’s often attractive to enterprises with existing procurement standards or custom appliances they can’t easily replace.
The trade-off is management burden. You control more, but you also inherit more. Cross-connects, smart hands, hardware lifecycle planning, spare parts, and escalation paths become your problem unless the provider layers in extra service.
Colocation usually works best for:
- Established infrastructure teams with documented operational runbooks
- Specialized hardware needs that don’t map neatly to hosted platforms
- Compliance-driven designs where equipment ownership matters
Managed bare metal fits teams that want dedicated performance without owning the facility layer
Bare metal is the practical middle ground. You still get dedicated hardware, but you don’t have to buy, stage, ship, and maintain physical servers yourself.
For virtualization clusters, multi-tenant application nodes, or game and database workloads, dedicated servers are often easier to predict than noisy shared environments. The key is matching server shape to workload:
| Model | Where it fits |
|---|---|
| Dual Intel Xeon E5-2690 V3 | Useful for Proxmox clusters, game server hosting, and multi-tenant VPS nodes |
| AMD EPYC 4584PX | Better for memory-intensive databases, AI/ML inference, and high-density virtualization |
| AMD Ryzen 9600X | Good for single-tenant applications, development systems, and high-clock workloads |
If your team needs dedicated resources but doesn’t want cage management and logistics overhead, this model often lands in the sweet spot.
A useful framing for cloud strategy choices appears in this comparison of private cloud vs public cloud, especially if you’re deciding whether dedicated infrastructure should remain fixed-function or become part of a more elastic internal platform.
Later in the evaluation, it helps to see one deployment model in motion:
Private cloud is for teams that need control plus operational speed
Private cloud is the model I recommend most often when an organization has outgrown basic VPS hosting but isn’t ready to run colocation like a facilities program. In such scenarios, Proxmox-based environments usually shine.
You get dedicated hardware under a virtualization layer, which gives you segmentation, snapshots, controlled resource allocation, and a path to clustering. That’s especially useful for businesses rethinking VMware cost structure, standardizing on KVM and LXC, or consolidating mixed workloads under one operational model.
Private cloud tends to be the strongest fit when you need:
- Dedicated performance with tenant isolation
- Faster provisioning than self-owned hardware
- Clear migration paths from legacy virtualization
- A manageable growth path for backup, replication, and HA design
If you’re choosing between colocation and hosted infrastructure, ask who will own the daily friction. The right answer often determines the right model before pricing ever enters the discussion.
For many SMBs, private cloud solves the core problem. They don’t need a cage. They need reliable infrastructure with root access, predictable performance, and someone accountable for the platform beneath it.
Navigating Costs and Contractual Agreements
Infrastructure invoices are often less transparent than provider websites suggest. That’s especially true when buyers compare colocation against managed hosting or private cloud on a line-item basis without accounting for the labor and add-on services wrapped into each model.
The first trap is assuming the base quote reflects the full operating cost. In colocation, extra charges often show up around remote hands, power usage behavior, interconnection, and after-hours work. None of those are unfair in themselves. They just need to be surfaced early.
What to ask before you sign
A strong buying process includes written answers to practical questions.
- Power billing: Is power billed as committed capacity, actual use, or a hybrid model?
- Cross-connect charges: Are recurring interconnection fees separate from cabinet pricing?
- Support scope: What does standard support include, and what triggers billable remote hands?
- Contract flexibility: What happens if your density, bandwidth, or footprint changes mid-term?
- Exit mechanics: How much work is required to migrate out cleanly if priorities shift?
The contract language that matters
Organizations often spend too much time on the headline monthly rate and not enough on the operating clauses. Read the SLA and service descriptions carefully. You want clarity on incident response boundaries, maintenance windows, hardware replacement responsibility, and how escalations are handled when multiple vendors are involved.
If energy strategy is part of your long-term planning, especially for owner-operated infrastructure, this overview of commercial solar financing options is a useful reference for understanding how businesses think about capital planning versus monthly operating expense on power-related projects. It won’t change your colocation contract directly, but it does sharpen the broader cost conversation.
When teams want a benchmark for structured colo pricing, reviewing a published data center colocation pricing approach can help them compare recurring charges more intelligently, especially when one provider bundles support and another unbundles everything.
Cheap infrastructure is expensive when the quote hides the operating model.
The buyers who get the best outcome usually don’t chase the lowest visible number. They look for the cleanest alignment between price, support responsibility, and expected growth.
Your Next Steps and Miami Data Center FAQs
Miami data centers matter because they combine strategic geography with dense connectivity options. That doesn’t mean every workload belongs there, and it doesn’t mean every business should buy the same way. The practical choice depends on your traffic patterns, support capacity, compliance needs, and appetite for infrastructure ownership.
If your team already runs hardware well and needs direct control, colocation can be the right tool. If you want dedicated performance without running the facility layer, managed bare metal is often simpler. If you need a platform that supports growth, virtualization, migration, and operational flexibility, private cloud usually provides the best balance.
A practical next-step checklist
Map your workloads
Separate customer-facing apps, internal systems, backup targets, and latency-sensitive services.Choose your support boundary
Decide what your team will own day to day. Be honest about after-hours operations.Test the network assumptions
Verify where users, partners, and external dependencies sit before locking in geography.Review migration risk
If you’re moving from legacy virtualization or aging hardware, build the landing zone before touching production.
Miami data center FAQs
Can we use Florida infrastructure if we don’t need a cabinet in Miami itself
Yes. Many businesses want Florida-based hosting benefits without taking on direct colocation overhead in Miami. In that case, hosted bare metal, VPS, or private cloud in the state can be a more practical fit than leasing space in a major interconnection building.
Is Miami always the right choice for disaster recovery
Not always. Miami can be useful in a broader resilience strategy, but disaster recovery design should be based on application dependency mapping, replication behavior, and risk separation. The right secondary site depends on what failure scenarios you’re trying to withstand.
How do we decide between bare metal and private cloud
Start with your operational model. If you need one or a few fixed-function dedicated systems, bare metal is usually cleaner. If you need multiple VMs or containers, policy control, staged migrations, or cluster growth, private cloud is usually easier to scale.
Can a small IT team manage this transition
Yes, if the operating model matches team capacity. Small teams get into trouble when they choose colocation for control but don’t have the time to own hardware lifecycle, incident response, and facility coordination. Hosted and managed models reduce that burden.
What if we’re moving away from VMware
That transition is common. The safest path is to inventory workloads, normalize resource assumptions, validate networking and backup behavior, and then move in phases. Proxmox-based private cloud is often a strong landing zone because it supports a more controllable cost and operations model than legacy virtualization sprawl.
If you’re evaluating Miami-adjacent infrastructure options and want a practical second opinion, ARPHost, LLC offers Florida-based VPS, bare metal, private cloud, colocation, backup, and managed IT services that can support anything from a simple hosted migration to a fully managed Proxmox environment.