

A lot of IT leaders are making this decision under pressure, not in a planning workshop. A key Linux admin just left. A VMware to Proxmox migration is behind. Your developers need a cleaner CI runner setup on VPS nodes. Finance wants predictable spend. Operations wants someone accountable when alerts fire at 2 a.m.
That's where the essential it managed services vs staff augmentation decision shows up. You're not comparing abstract sourcing models. You're deciding whether you need more skilled hands inside your operating model, or whether you need a partner to own an outcome.
If you're already feeling the pull between speed, control, and accountability, the bigger issue is usually operational design, not staffing alone. This broader pressure is part of the IT skills gap and outsourcing imperative.

The Modern IT Dilemma Headcount or Outcomes
A common example looks like this. A company runs customer apps on a mix of KVM VPS instances, a few bare metal database servers, and a small Proxmox cluster for internal systems. Growth is fine, but the environment got complicated faster than the team did. Backups need verification. Patch windows keep slipping. One firewall rule change can break a billing app. Nobody wants to hire a full-time specialist for every narrow problem.
That's why the decision usually narrows to two options. Staff augmentation gives you a specialist you direct. Managed services gives you a provider that owns delivery for a defined function.
The distinction matters most when the infrastructure is business-critical. If you need a contractor to help tune Ceph storage, clean up Terraform modules, or automate bare metal provisioning with PXE and config management, extra hands can be the right move. If you need dependable monitoring, patching, incident response, backup verification, and uptime accountability across production systems, buying outcomes is usually the more durable decision.
The wrong model rarely fails on day one. It fails three months later, when tickets pile up, nobody owns the runbook, and every issue turns into a meeting.
In practice, good CTOs don't ask which model is better in general. They ask a sharper question: Where do we need control, and where do we need guaranteed execution? That's the question that prevents expensive confusion later.
Defining the Two Sourcing Models
The cleanest way to understand this choice is to separate inputs from outputs.
Staff augmentation means you rent expertise
With staff augmentation, you add outside talent to your team, but your team still manages the work. You set priorities, run standups, review changes, approve maintenance windows, and own the result.
That makes it useful when you already have an internal operating rhythm and just need narrow capacity. Examples include bringing in a Proxmox engineer for cluster rebalancing, a DevOps specialist to refactor CI/CD pipelines, or a storage admin to help with replication design on bare metal hosts.
If your challenge is finding the right specialist in the first place, some teams benefit from outside perspective on recruiting top tech talent, especially when the need is highly specific and internal hiring channels are slow.
Managed services means you buy a service outcome
Managed services works differently. You're not buying an individual person's time. You're outsourcing responsibility for a function. According to AhelioTech's comparison of staff augmentation and managed services, staff augmentation is best when the client retains daily direction and wants narrow specialist capacity, while managed services fits situations where the provider owns execution end-to-end under SLAs. The same comparison describes staff augmentation as input-oriented and billed mainly by time worked, with risk retained by the client, while managed services is output-oriented, typically billed as a recurring retainer or fixed monthly fee, with responsibility transferred to the provider.
Core distinction: Staff augmentation gives you a person to manage. Managed services gives you a function with accountability attached.
That difference changes day-to-day operations. If you hire an augmented systems engineer to harden Linux VPS nodes, your team still needs to define scope, validate changes, and document the environment. If you outsource server operations under a managed model, the provider should own recurring tasks, escalation handling, and service reporting under the agreement.
A lot of confusion disappears once you label the models correctly:
- Staff augmentation is a capacity model.
- Managed services is an operating model.
Why this matters in real infrastructure
For server and network operations, this isn't a semantic difference. It changes who carries the pager burden and who absorbs execution risk. If your team can manage the moving parts, staff augmentation can be efficient. If your team is already overloaded, adding another person to supervise often doesn't solve the root problem.
For a deeper look at outsourced operating models, IT outsourcing services are best evaluated by who owns delivery, documentation, and continuity, not just who logs the hours.
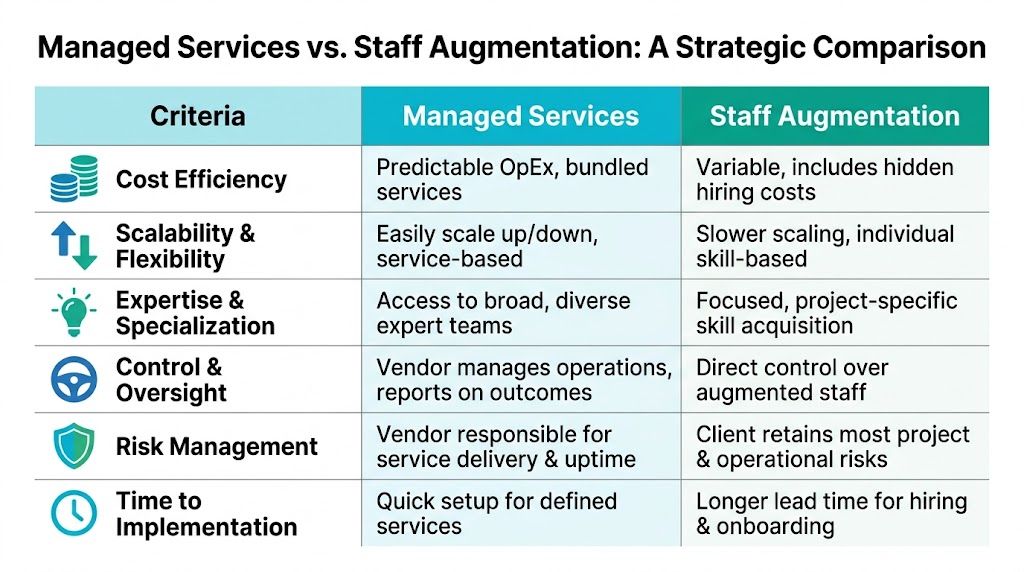
A Criteria-Based Comparison Analysis
The best comparisons start with operational criteria, not vendor marketing. Before you decide, map the work across control, measurement, risk, and scale.
Here's the fast view first.
| Criterion | Staff Augmentation | Managed Services |
|---|---|---|
| Primary purchase | Specialist time and expertise | Defined service outcome |
| Daily management | Client directs work | Provider runs delivery |
| Billing model | Usually time-based | Usually recurring retainer or fixed monthly |
| Best fit | Short-term projects, specialist gaps | Ongoing operations and support |
| Risk position | Client keeps most operational risk | Provider takes more delivery responsibility |
| Success lens | Productivity, integration, milestones | Uptime, response, incident handling, SLA adherence |
How each model behaves under pressure
A cloud migration project is a good test. If you're moving workloads from VMware to Proxmox and your internal team knows the application dependencies, maintenance windows, and rollback paths, an augmented engineer can accelerate execution without taking over architecture decisions.
The same logic breaks down for steady-state operations. If you need patching, backup checks, monitoring, malware response, and capacity planning across mixed infrastructure every week, person-based sourcing starts to create management drag. You're still assigning tasks. You're still checking work. You're still carrying the incident burden.
Managed services usually wins when the work is repetitive, ongoing, and operationally sensitive.
Measurement tells you which model fits
A practical benchmark is how success gets measured. According to Framework IT's guidance on the two models, staff augmentation is measured by resource productivity, integration speed, knowledge transfer, milestone completion, and deliverable quality, and augmented staff often become productive in about 2-4 weeks. The same source says managed services is measured through outcome KPIs such as uptime, ticket resolution time, security-incident frequency, compliance audit results, and user satisfaction, with SLA adherence as the core technical control.
That distinction is useful because it exposes a common mistake. Teams often buy staff augmentation for work they want measured like a service. If the requirement sounds like “keep these systems healthy,” “reduce backup failures,” or “maintain 24/7 visibility,” you're already talking about outcomes, not labor.
For a broader sourcing lens, this perspective on how to choose your tech partner is useful because it forces the conversation toward ownership and operating fit, not just resumes.
Here's a practical split by environment type:
| Environment need | Better default |
|---|---|
| Temporary Proxmox cluster cleanup | Staff augmentation |
| Bare metal OS standardization project | Staff augmentation |
| Ongoing VPS monitoring and patching | Managed services |
| Incident response coordination for recurring ops | Managed services |
| Short development sprint with internal lead | Staff augmentation |
| 24/7 infrastructure reliability requirement | Managed services |
Cost model is only part of the story
Time-based contracts can look cheaper at first, especially for focused projects. If you only need one specialist for a narrow task, paying for hours may be sensible. But time-based spend doesn't include your management overhead, review time, internal escalation load, or the cost of uneven documentation.
Recurring managed service pricing can feel less flexible, but it aligns better with steady-state infrastructure. You're paying for process, tooling, coverage, and accountability together. That matters when the job includes watchfulness, not just engineering.
This video gives a useful high-level framing before you get into contract specifics.
When comparing proposals, it helps to review different managed services pricing models through the lens of what work is bundled, what is excluded, and who owns remediation versus notification.
Uncovering Hidden Costs and Operational Risks
Most comparisons stop at control versus convenience. That's too shallow for production infrastructure.
The more useful question is this: What gets expensive when something goes wrong?
Staff augmentation failure modes
The biggest hidden risk with staff augmentation is continuity. According to Torchlight's analysis of the decision, a key risk is knowledge concentration and turnover when a contractor leaves. In real environments, that looks like undocumented cron jobs, one-off backup scripts, firewall exceptions nobody understands, or a Proxmox node tuned by memory rather than by runbook.
“Cheap” labor gets expensive. The hourly rate might look acceptable, but the business pays later through rework, delayed incident response, and forensic digging when systems drift.
Typical warning signs include:
- Single-operator logic: One contractor knows how replication was configured, but nobody else can validate failover.
- Thin documentation: The wiki has screenshots, not procedures.
- Slow handoffs: Offboarding starts only after the next incident exposes the gap.
Managed services failure modes
Managed services has its own trap. The same Torchlight analysis notes that managed services can create vendor dependency when exit terms and data portability are weak. That risk is very real in hosting and cloud environments.
A provider becomes dangerous when they control the service and obscure the environment. If they keep weak documentation, resist access transparency, or make migrations painful, the client can lose practical control even when the service appears stable.
Operational rule: Never outsource a critical function without clarifying how you would leave it.
That means asking for documented configurations, credential ownership boundaries, asset inventories, backup visibility, and transition procedures before the contract starts, not after trust breaks down.
Failure-mode cost is what the CFO should care about
If the business runs revenue-generating sites, customer portals, internal ERP, or voice systems on hosted infrastructure, continuity risk often matters more than hourly differences between sourcing models. A missed patch window on a noncritical lab VM is one thing. A poorly documented production storage node is another.
Good sourcing decisions reduce the blast radius of normal human events. People leave. Vendors change. Projects slip. The better model is the one that keeps those events from turning into outages.
A Scoring Checklist for Your Business Needs
This is the simplest way to make the decision without turning it into philosophy. Score each statement from 1 to 5.
Use 1 if the statement is not true for your environment. Use 5 if it is strongly true.

Score for staff augmentation fit
Add points if these statements sound like your situation:
- We already have a strong technical lead who can assign tasks, review work, and own the backlog.
- The need is temporary or tightly scoped, such as a migration, cluster redesign, or automation sprint.
- We need a narrow skill set, like Proxmox storage tuning, Kubernetes ingress cleanup, or IaC refactoring.
- We want direct engineering control over how the work is executed.
- The function is close to product delivery, where internal context matters more than outsourced process.
Score for managed services fit
Add points if these statements sound closer:
- We need consistent operational coverage, not just project execution.
- Uptime, ticket handling, patching, and security response matter more than who performs the work.
- Our internal team lacks bandwidth to supervise day-to-day infrastructure tasks.
- We need predictable service accountability, including clearly defined responsibilities.
- The workload is recurring, such as monitoring VPS fleets, maintaining web hosting stacks, or running backup and recovery routines.
If you score high on both sides, that usually points to a hybrid model rather than indecision.
How to interpret your results
If your staff augmentation score is clearly higher, you likely need specialist capacity while keeping management in-house. If your managed services score is higher, you're probably trying to solve an operations problem with labor, which tends to create friction.
If the scores are close, split the work by type:
- Project work stays with augmented specialists.
- Run-state operations move to managed service coverage.
That same split often appears outside infrastructure as well. Teams that already think carefully about execution systems, like this guide to emailing strategy, usually make better sourcing calls because they distinguish between campaign design and ongoing operational discipline. IT works the same way.
One last test
Ask one hard question before signing anything:
If the lead person disappears tomorrow, do we still have process continuity?
If the answer is no, don't confuse staffing with resilience.
Real-World Infrastructure Scenarios
Some workloads clearly belong in one model. Others don't. Most mature environments end up hybrid.

Scenario one where staff augmentation is the right call
Your team is migrating a virtual estate from VMware to Proxmox VE. Internal staff already knows the application map, the maintenance constraints, and which legacy workloads need special handling. What they don't have is enough hands-on Proxmox depth to redesign storage layouts, validate cluster behavior, and script VM conversion efficiently.
That's a strong staff augmentation use case. Bring in a specialist for the migration window. Keep architecture ownership, cutover authority, and rollback control internal.
The same applies to jobs like:
- Bare metal provisioning standardization using templates and config management
- Ceph tuning inside a private virtualization environment
- Firewall policy cleanup ahead of an audit or datacenter move
Scenario two where managed services is the better fit
A business runs several customer-facing sites, internal collaboration tools, and email workloads across VPS, shared hosting, and dedicated servers. Incidents don't happen all at once, but they happen often enough that someone always needs to check logs, apply updates, review alerts, verify backups, and catch early signs of trouble.
That's managed service territory. The requirement is continuity, not just skill.
According to Virtido's guide to managed IT services vs staff augmentation, modern IT strategy often uses a hybrid approach. Organizations may use managed services for baseline IT operations and risk management while using staff augmentation for specific development projects, driven in part by automation and advanced tooling that lets an MSP's tech stack scale ongoing maintenance more efficiently than adding individual headcount.
Where automation changes the calculus
This matters more now because observability, automation, and standardized runbooks reduce the value of solving every recurring task with another person. For recurring work, a well-tooled provider can often handle monitoring, patch orchestration, backup verification, and routine remediation with more consistency than an internally supervised contractor model.
Automation doesn't eliminate the need for experts. It changes where experts create value. Engineers should spend time on migration logic, architecture, and application behavior. Tooling should carry as much routine operational load as possible.
Questions to Ask Your Next IT Partner
Whether you're evaluating staff augmentation firms or managed providers, weak questions lead to polished but useless answers. Ask questions that expose how work gets done.
For staff augmentation, ask these first:
- Who manages priorities day to day?
- How do you document handoff knowledge before the engagement ends?
- What happens if the assigned specialist becomes unavailable mid-project?
- How do you validate technical fit for niche platforms like Proxmox, KVM, or Linux storage stacks?
For managed services, ask harder operational questions:
- What exactly is included in monitoring, patching, backup verification, and incident response?
- What are the service boundaries between notification and remediation?
- How is documentation maintained, and how do clients access it?
- What security tooling is included for hosted websites and servers, such as Imunify360, CloudLinux OS, or Webuzo-based management workflows?
- How do you support high-availability VPS environments, private cloud clusters, or bare metal fleets without creating opaque dependencies?
- What does offboarding look like if we need to transition the environment elsewhere?
A strong provider answers with process, tooling, access boundaries, and escalation logic. A weak one answers with adjectives.
The same standard applies to commercial terms. If the provider can't explain what they own, what you own, and how service continuity is preserved, keep looking.
If you're weighing outsourced operations against specialist staffing, ARPHost, LLC is worth reviewing for both infrastructure depth and hands-on support. Their stack spans VPS hosting, secure web hosting bundles, bare metal servers, Dedicated Proxmox Private Clouds, colocation, and fully managed IT services. If your priority is outcome-driven support, request a managed services quote. If you need infrastructure first, explore their hosting and private cloud options to match the right sourcing model to the right workload.